Understanding ALB
ALB (Another Load Balancer) is a Kubernetes Gateway powered by OpenResty with years of production experience from Alauda.
TOC
Core componentsQuick StartDeploy the ALB OperatorDeploy an ALB InstanceRun a demo applicationRelationship between ALB, ALB Instance, Frontend/FT, Rule, Ingress, and ProjectIngressIngress ControllerALBALB InstanceALB-OperatorFrontend (abbreviation: FT)RULEALB LeaderProjectAdditional resources:Core components
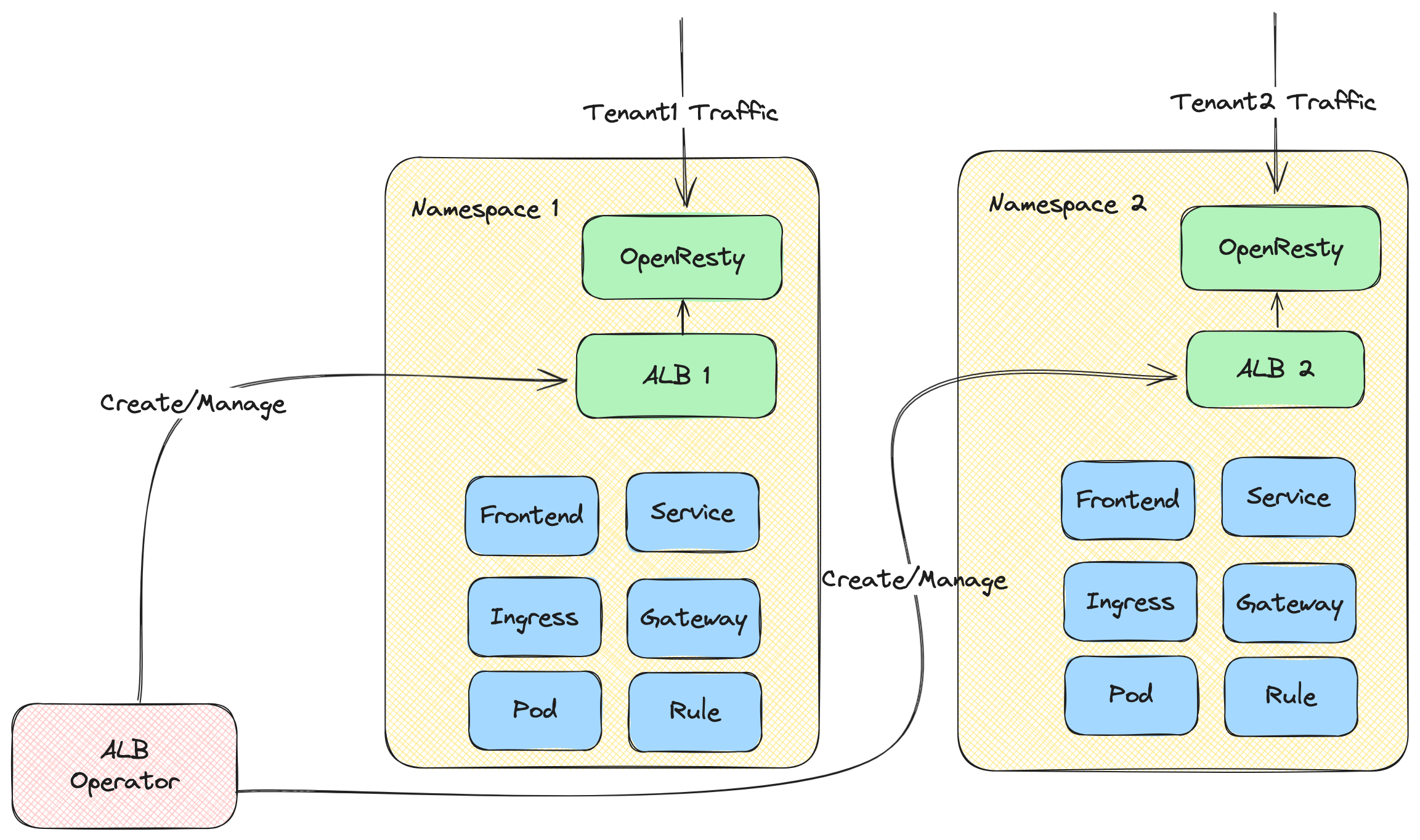
- ALB Operator: An operator that manages the lifecycle of ALB instances. It watches ALB CRs and creates/updates instances for different tenants.
- ALB Instance: An ALB instance includes OpenResty acting as the data plane and a Go controller as the control plane. The Go controller monitors various CRs (Ingress, Gateway, Rule, etc.) and converts them into ALB-specific DSL rules. OpenResty then uses these DSL rules to match and process incoming requests.
Quick Start
Deploy the ALB Operator
- Create a cluster.
Deploy an ALB Instance
Run a demo application
Now you can access the app via curl http://${ip}
Relationship between ALB, ALB Instance, Frontend/FT, Rule, Ingress, and Project
LoadBalancer is a key component in modern cloud-native architectures, serving as an intelligent traffic router and load balancer.
To understand how ALB works in a Kubernetes cluster, we need to understand several core concepts and their relationships:
- ALB itself
- Frontend (FT)
- Rules
- Ingress resources
- Projects
These components work together to enable flexible and powerful traffic management capabilities.
The following explains how these concepts work together in the request path. Detailed introductions for each concept are covered in separate articles.
In a request-calling chain:
- A client sends an HTTP/HTTPS/other protocol request, and finally the request will arrive on a pod of ALB, and the pod (an ALB instance) will start to handle this request.
- This ALB instance finds a rule which could match this request.
- If needed, modify/redirect/rewrite the request based on the rule.
- Find and select one pod IP from the services which the rule configured. And forward the request to the pod.
Ingress
Ingress is a resource in Kubernetes, used to describe what request should be sent to which service.
Ingress Controller
A program that understands Ingress resource and will proxy request to service.
ALB
ALB is an Ingress controller.
In Kubernetes cluster, we use the alb2 resource to operate an ALB. You could use kubectl get alb2 -A to view all the ALBs in the cluster.
ALBs are created by users manually. Each ALB has its own IngressClass. When you create an Ingress, you can use .spec.ingressClassName field to indicate which Ingress controller should handle this Ingress.
ALB Instance
ALB also is a Deployment (bunch of pods) running in the cluster. Each pod is called an ALB instance.
Each ALB instance handles requests independently, but all instances share Frontend (FT), Rule, and other configurations belonging to the same ALB.
ALB-Operator
ALB-Operator, a default component deployed in the cluster, is an operator for ALB. It will create/update/delete Deployment and other related resources for each ALB according to the ALB resource.
Frontend (abbreviation: FT)
FT is a resource defined by ALB itself. It is used to represent the ALB instance listening ports.
FT could be created by ALB-Leader or user manually.
Cases of FT created by ALB-Leader:
- If Ingress has certificate, we will create FT 443 (HTTPS).
- If Ingress has no certificate, we will create FT 80 (HTTP).
RULE
RULE is a resource defined by ALB itself. It takes the same role as the Ingress, but it is more specific. A RULE is uniquely associated with a FT.
RULE could be created by ALB-Leader or user manually.
Cases of RULE created by ALB-Leader:
- Sync Ingress to RULE.
ALB Leader
In multiple ALB instances, one will be elected as leader. The leader is responsible for:
- Translating the Ingress into Rules. We will create Rule for each path in the Ingress.
- Creating FT needed by Ingress. For example, if Ingress has certificate we will create FT 443 (HTTPS), if Ingress has no certificate we will create FT 80 (HTTP).
Project
From the perspective of ALB, Project is a set of namespaces.
You could configure one or more Projects in an ALB. When ALB Leader translates the Ingress into Rules, it will ignore Ingress in namespaces which do not belong to the Project.