监控与告警
针对虚拟机的 CPU、内存、存储和网络进行监控和告警。为了便于及时告警,还可以配置通知策略。
直观呈现的监控数据可用于为运维巡检或性能调优提供决策支持,而完善的告警和通知机制将有助于保障虚拟机的稳定运行。
目录
监控
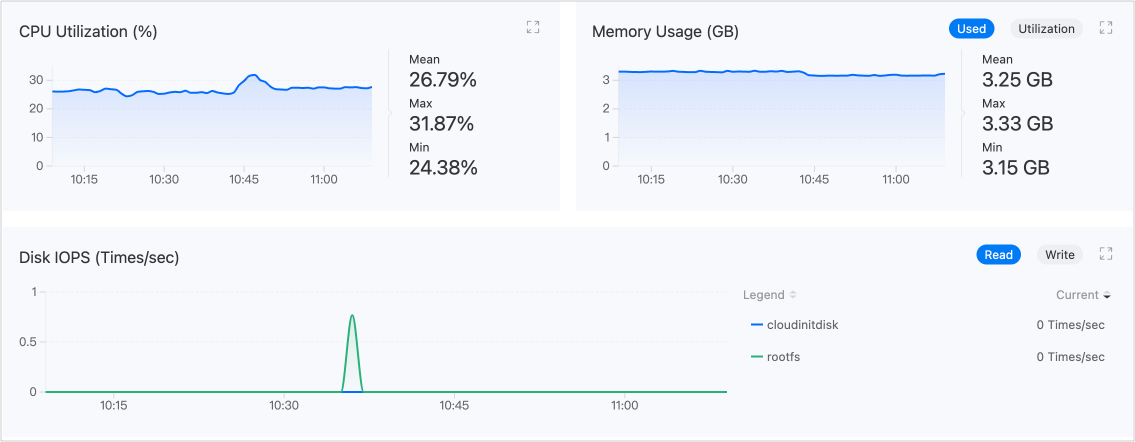
平台默认采集虚拟机常用的性能监控指标,包括 CPU、内存、存储和网络。进入 Virtualization > Virtual Machines,在虚拟机详情的 Monitoring 标签页中,可以查看指标的实时监控数据。
告警
配置告警策略
要启用告警,必须先创建告警策略。告警策略描述了您希望监控的对象、希望告警的条件,以及如何接收相关告警通知。进入 Container Platform > Virtualization > Virtual Machines,在虚拟机详情的 Alerts 标签页点击 Create Alert Policy 完成配置。
| 参数 | 描述 |
|---|---|
| Alert Type | - Metric Alert:监控对象为平台预定义的指标,如 Memory Usage Rate。 - Event Alert:监控对象为事件的原因,即虚拟机转变到当前状态的原因,例如 BackOff、Pulling、Failed。 |
| Trigger Condition | 由比较运算符、告警阈值和持续时间组成。通过将实时监控结果与设置的阈值进行比较,判断是否触发告警。 如果设置了持续时间,平台还会比较监控对象处于告警状态的持续时间。 |
| Alert Level | - Hint:监控对象存在预期问题,暂时不会影响业务运行,但存在潜在风险。例如 CPU 使用率超过 70% 持续 3 分钟。 - Warning:监控对象存在运行风险,若不及时处理可能影响正常业务运行。例如 CPU 使用率超过 80% 持续 3 分钟。 - Serious:监控对象存在已知问题,可能导致平台功能异常,影响正常业务运行。 - Disaster:监控对象发生故障,导致平台服务中断、数据丢失,影响严重。 |
提示:虚拟机告警功能与平台通用告警功能类似。更多详细配置指导,请参见通用 Alerts 文档。
处理告警
进入 Alerts 标签页,如有告警状态策略提示,请及时处理。
绑定通知策略
除了在 Alerts 标签页实时告警外,平台还支持通过邮件、短信等方式将告警信息发送给相关人员,通知其采取必要措施解决问题或防止故障。通知策略需联系管理员进行设置。