理解 ALB
ALB(Another Load Balancer)是一个基于 OpenResty 的 Kubernetes Gateway,拥有来自 Alauda 多年生产环境的经验。
目录
核心组件
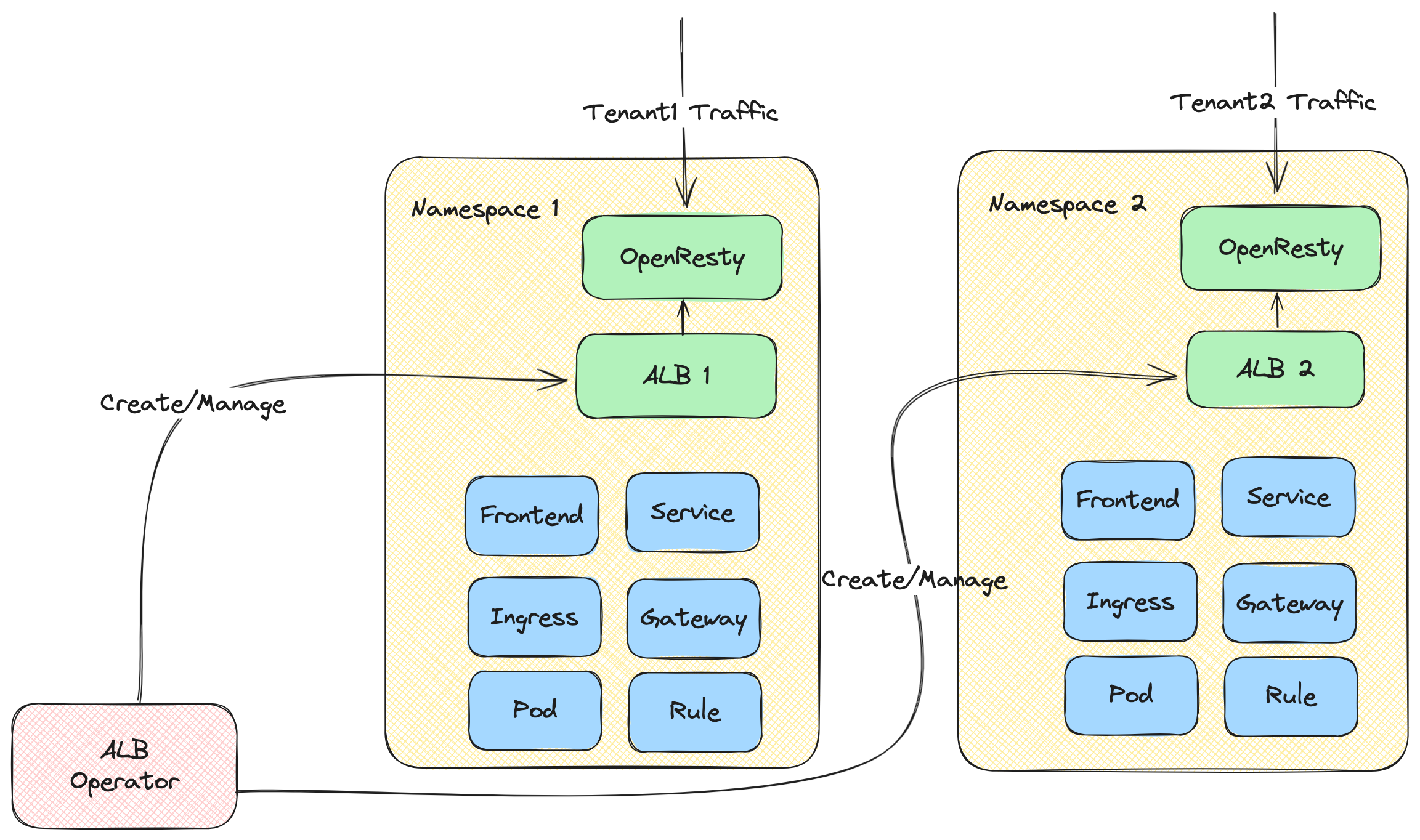
- ALB Operator:管理 ALB 实例生命周期的 operator。它监控 ALB CR 并为不同租户创建/更新实例。
- ALB Instance:ALB 实例包含作为数据平面的 OpenResty 和作为控制平面的 Go 控制器。Go 控制器监控各种 CR(Ingress、Gateway、Rule 等),并将它们转换为 ALB 专用的 DSL 规则。OpenResty 使用这些 DSL 规则来匹配和处理传入请求。
快速开始
部署 ALB Operator
- 创建一个集群。
-
-
部署 ALB 实例
运行示例应用
现在你可以通过 curl http://${ip} 访问该应用。
ALB、ALB 实例、Frontend/FT、Rule、Ingress 和 Project 之间的关系
LoadBalancer 是现代云原生架构中的关键组件,作为智能流量路由和负载均衡器。
要理解 ALB 在 Kubernetes 集群中的工作原理,我们需要了解几个核心概念及其关系:
- ALB 本身
- Frontend (FT)
- Rules
- Ingress 资源
- Projects
这些组件协同工作,实现灵活且强大的流量管理能力。
以下说明这些概念在请求路径中的协作方式。每个概念的详细介绍在单独文章中讲解。
在请求调用链中:
- 客户端发送 HTTP/HTTPS/其他协议请求,最终请求会到达 ALB 的某个 pod,该 pod(即 ALB 实例)开始处理请求。
- 该 ALB 实例找到一个能够匹配该请求的规则。
- 如有需要,根据规则修改/重定向/重写请求。
- 从规则配置的服务中找到并选择一个 pod IP,将请求转发给该 pod。
Ingress
Ingress 是 Kubernetes 中的资源,用于描述请求应发送到哪个服务。
Ingress Controller
理解 Ingress 资源并将请求代理到服务的程序。
ALB
ALB 是一种 Ingress controller。
在 Kubernetes 集群中,我们使用 alb2 资源来操作 ALB。你可以使用 kubectl get alb2 -A 查看集群中所有 ALB。
ALB 由用户手动创建。每个 ALB 有自己的 IngressClass。创建 Ingress 时,可以使用 .spec.ingressClassName 字段指定由哪个 Ingress controller 处理该 Ingress。
ALB 实例
ALB 也是集群中运行的 Deployment(多个 pod)。每个 pod 称为一个 ALB 实例。
每个 ALB 实例独立处理请求,但所有实例共享属于同一 ALB 的 Frontend (FT)、Rule 及其他配置。
ALB-Operator
ALB-Operator 是集群中默认部署的组件,是 ALB 的 operator。它根据 ALB 资源创建/更新/删除 Deployment 及其他相关资源。
Frontend(简称 FT)
FT 是 ALB 自定义的资源,用于表示 ALB 实例监听的端口。
FT 可以由 ALB-Leader 或用户手动创建。
ALB-Leader 创建 FT 的情况:
- 如果 Ingress 有证书,会创建 FT 443(HTTPS)。
- 如果 Ingress 无证书,会创建 FT 80(HTTP)。
RULE
RULE 是 ALB 自定义的资源。 它的作用类似于 Ingress,但更具体。 一个 RULE 唯一关联一个 FT。
RULE 可以由 ALB-Leader 或用户手动创建。
ALB-Leader 创建 RULE 的情况:
- 将 Ingress 同步为 RULE。
ALB Leader
在多个 ALB 实例中,会选举出一个 leader。 Leader 负责:
- 将 Ingress 转换为 Rules。 会为 Ingress 中的每个路径创建对应的 Rule。
- 创建 Ingress 需要的 FT。 例如,Ingress 有证书则创建 FT 443(HTTPS),无证书则创建 FT 80(HTTP)。
Project
从 ALB 角度看,Project 是一组 namespace。
你可以在 ALB 中配置一个或多个 Project。 当 ALB Leader 将 Ingress 转换为 Rules 时,会忽略不属于 Project 的 namespace 中的 Ingress。