Alert Policies
Вы можете самостоятельно создать пользовательскую политику оповещений на платформе ASM или быстро создать её с помощью шаблона, предоставленного администратором в управлении платформой.
Содержание
Создание персонализированных политик оповещенийПредварительные условияБыстрый стартОсновная информацияПравила оповещенийResource AlertsEvent AlertsПроверка результатаНастройка политики уведомлений (опционально)ЗавершениеСоздание политик оповещений с использованием шаблоновПредварительные условияШагиПоследующие операцииПросмотр оповещений в реальном времениОтключение/включение правил оповещенийСоздание персонализированных политик оповещений
На основе данных мониторинга, логов и событий платформы, в сочетании с функционалом уведомлений платформы, создавайте метрики оповещений, пользовательские оповещения, оповещения по логам и оповещения по событиям для сервисов и вычислительных компонентов в рамках одного namespace текущей сервисной сетки. При возникновении аномалий в ресурсах, на которые направлена политика оповещений, или при достижении мониторинговыми данными заранее заданного состояния предупреждения, автоматически срабатывают оповещения и отправляются уведомления.
Предварительные условия
-
Если требуется, чтобы конфигурация оповещений автоматически отправляла уведомления, заранее обратитесь к администратору платформы для настройки Notification Policy в разделе Platform Management.
-
Убедитесь, что в кластере, где расположены ресурсы политики оповещений, развернут компонент мониторинга, чтобы созданные на основе метрик мониторинга политики оповещений были активны.
-
Убедитесь, что в кластере, где расположены ресурсы политики оповещений, развернут компонент Elasticsearch, чтобы созданные на основе логов и результатов запросов по событиям политики оповещений были активны.
Быстрый старт
-
В левой навигационной панели нажмите Alerts > Rules.
-
Нажмите Create Rule.
Основная информация
В области Basic Information настройте основную информацию политики оповещений. Сначала необходимо выбрать типы оповещений.
Resource Alerts
Типы оповещений, разделённые по категориям мониторинговых ресурсов, например, следующие сценарии:
- Можно непрерывно мониторить некоторые или все Deployments в текущем namespace и срабатывать на оповещение, если их статус развертывания не Running.
- Можно непрерывно мониторить конкретный микросервис в текущем namespace и срабатывать на оповещение, если процент ошибок трафика сервиса превышает 20%.
Советы:
- Если не выбраны параметры, связанные с объектом ресурса, по умолчанию выбирается Any. Последующее удаление/добавление объектов ресурсов приведёт к отвязке/автоматической привязке политики оповещений.
- Services — необязательный параметр, также можно указать, введя имя и нажав Enter. При вводе поддерживается сопоставление имён сервисов с помощью регулярных выражений, например
cert.*.
Event Alerts
Типы оповещений, разделённые по событиям K8s, например, следующий сценарий:
Для Pod с именем Nginx в текущем namespace после добавления правила сопоставления можно срабатывать на оповещение, если статус Pod — Failed.
Совет: Если в правилах сопоставления ничего не выбрано, будут выбраны все ресурсы в рамках некоторого ресурса, и последующее удаление/добавление ресурсов приведёт к отвязке/автоматической привязке политики оповещений.
Быстрые советы
Если вы хотите непрерывно мониторить сервис OpenTelemetry, выберите Resource Alerts и в качестве метода управления выберите OpenTelemetry.
Правила оповещений
После выбора типа оповещения и настройки области мониторинга согласно вышеуказанным инструкциям можно добавить соответствующие правила оповещений.
Resource Alerts
-
В области Rules нажмите Add Alert Rule.
Примечание: График мониторинга, отображаемый над диалоговым окном, предоставляет предварительный просмотр данных метрик или выражений мониторинга, который меняется в реальном времени в зависимости от вашего выбора. Вы можете перепроверить введённые данные по графику.

-
Выберите тип оповещения и настройте правила оповещений согласно следующим инструкциям.
Metric Alerts: Выберите предустановленные платформой метрики оповещений.
Custom Alerts
Пожалуйста, следуйте инструкциям ниже для ввода соответствующих данных:
- Metric Name: Введите имя текущей пользовательской метрики для удобства управления и поиска.
- Expression: Необходимо добавить конкретное правило метрики в соответствии с вашим сценарием мониторинга для удовлетворения продвинутых потребностей мониторинга и оповещений. Требуется вручную ввести метрики и выражения, распознаваемые Prometheus, например:
rate(node_network_receive_bytes{instance="$server",device!~"lo"}[5m]). - Unit: Единица измерения метрики мониторинга, может быть введена вручную как пользовательская единица.
- Legend Parameters: Для удобства отображения и просмотра данных в легенде можно ввести метку мониторинговых данных как ключ, а соответствующее ключу
valueбудет служить идентификатором в легенде. Формат ввода:{{.key}}.
Инструкция по настройке параметров легенды: После ввода корректного выражения наведите курсор на запись в списке статистики ранжирования справа от графика мониторинга над диалоговым окном, чтобы просмотреть все метки данных. Как показано на рисунке.
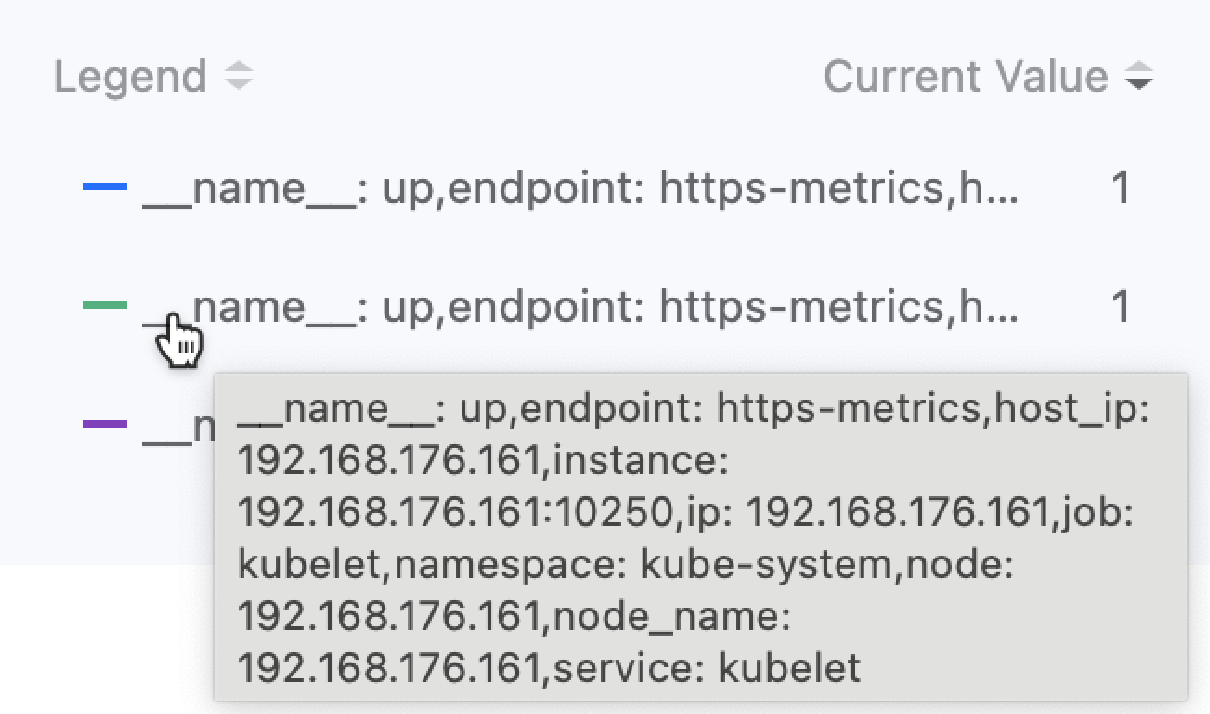
Например: Метки мониторинговых данных, полученных через выражение up{service="kubelet"}, включают "__name__":"up","endpoint":"https-metrics","instance":"192.168.18.2:10250","job":"kubelet","namespace":"kube-system","node":"192.168.18.2","service":"kubelet". Если вы хотите использовать целевой endpoint, собирающий данные, в качестве идентификатора легенды, можно ввести параметр легенды {{.instance}}. Эффект отображения показан на следующем рисунке.
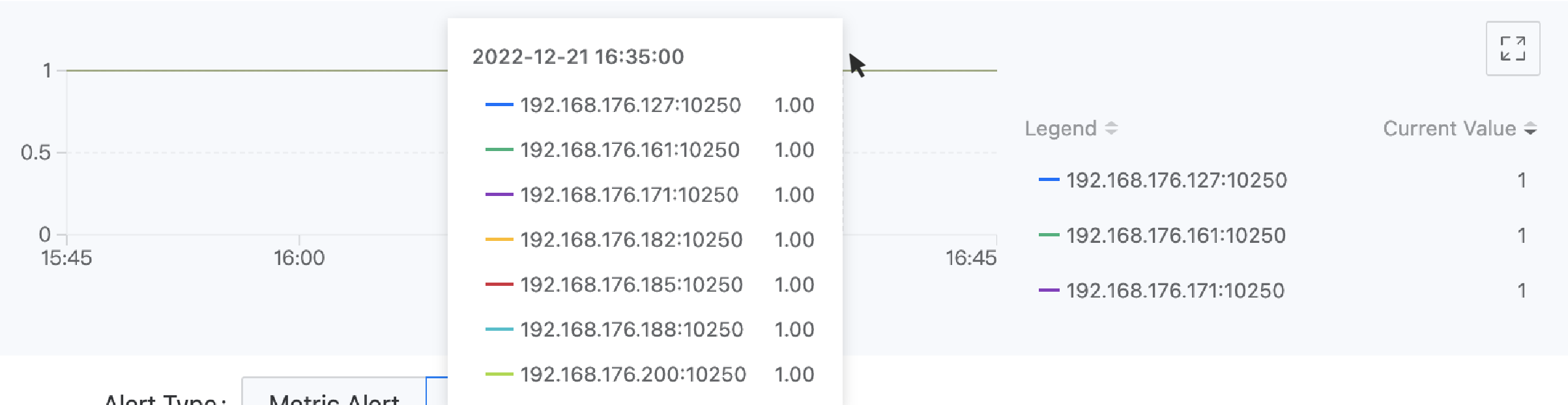
- Введите условия срабатывания
Trigger Condition состоит из операторов сравнения, порогов оповещения и длительности (опционально). Результат сравнения между текущим значением/количеством логов/количеством событий мониторинговых метрик и порогом оповещения, а также длительность, в течение которой текущее значение находится в пределах порога, определяют, будет ли срабатывать оповещение.
Операторы сравнения: > (больше), >= (больше или равно), == (равно), <= (меньше или равно), < (меньше), != (не равно).
Порог: Порог оповещения принимает только числа. Если для выбранного элемента мониторинга blackbox метод обнаружения — HTTP, а имя метрики выбрано как cluster.blackbox.http.status.code, порог оповещения — это код статуса HTTP-запроса, поддерживается ввод только трёхзначного положительного целого числа, например: 200.
Длительность: Время, в течение которого текущее значение метрики остаётся в пределах порога оповещения. При достижении указанного времени срабатывает оповещение.
- Выберите уровень оповещения
Уровень оповещения правила, задаваемый пользователем, позволяет установить разумный уровень оповещения в зависимости от влияния ресурсов, соответствующих правилу, на бизнес-процессы.
Critical: Отказ ресурса, соответствующего правилу оповещения, приводит к прерыванию бизнес-процессов платформы, потере данных и значительному воздействию. Например: Значение статуса здоровья узла равно 0 (недоступен) в течение 3 минут.
High: Ресурс, соответствующий правилу оповещения, имеет известные проблемы, которые могут вызвать сбои в функциональности платформы, влияя на нормальную работу. Например: Количество доступных pod-групп вычислительного компонента равно 0 в течение 3 минут.
Medium: Ресурс, соответствующий правилу оповещения, имеет операционные риски. При несвоевременном устранении может повлиять на нормальную работу. Например: Использование CPU узла превышает 80% в течение 3 минут.
Low: Ресурс, соответствующий правилу оповещения, имеет ожидаемые проблемы, которые в краткосрочной перспективе не влияют на бизнес, но представляют потенциальные риски. Например: Использование CPU узла превышает 70% в течение 3 минут.
- Нажмите Add.
Event Alerts
-
После выбора типа оповещения Event Alerts в области Rules нажмите Add Alert Rule.
-
Выберите временной диапазон. Например: Если временной диапазон установлен на 5 минут, после создания оповещения, если количество событий, удовлетворяющих условиям, достигается в любой 5-минутный период, срабатывает оповещение.
-
Элементы мониторинга событий
Мониторьте уровень события или причину события выбранных событий.
- Event Severity: Уровень серьёзности, определённый для выбранного события, например Warning.
- Event Reason: Конкретная причина события (Reason, например BackOff, Pulling, Failed и т. д.), подтверждается нажатием клавиши Enter. Можно ввести несколько значений, при запросе между ними действует логика
or, то есть записи, содержащие любую из указанных причин события, соответствуют критериям запроса.
-
Условия срабатывания
Условия срабатывания используют операторы сравнения для определения необходимости оповещения на основе количества записей событий.
-
Уровень оповещения
Уровень оповещения правила, задаваемый пользователем, позволяет установить разумный уровень оповещения в зависимости от влияния ресурсов, соответствующих правилу, на бизнес-процессы.
Critical: Отказ ресурса, соответствующего правилу оповещения, приводит к прерыванию бизнес-процессов платформы, потере данных и значительному воздействию. Например: Значение статуса здоровья узла равно 0 (недоступен) в течение 3 минут.
High: Ресурс, соответствующий правилу оповещения, имеет известные проблемы, которые могут вызвать сбои в функциональности платформы, влияя на нормальную работу. Например: Количество доступных pod-групп вычислительного компонента равно 0 в течение 3 минут.
Medium: Ресурс, соответствующий правилу оповещения, имеет операционные риски. При несвоевременном устранении может повлиять на нормальную работу. Например: Использование CPU узла превышает 80% в течение 3 минут.
Low: Ресурс, соответствующий правилу оповещения, имеет ожидаемые проблемы, которые в краткосрочной перспективе не влияют на бизнес, но представляют потенциальные риски. Например: Использование CPU узла превышает 70% в течение 3 минут.
-
Нажмите Add.
Проверка результата
Независимо от того, выбрали ли вы пользовательские оповещения или оповещения по событиям, после добавления всплывающее окно закрывается, а добавленные записи отображаются в списке Rules на странице создания политики оповещений.
Настройка политики уведомлений (опционально)
Если вы уже создали политику уведомлений на странице управления, в области Policy Configuration можно настроить действия уведомлений после срабатывания оповещения.
-
Нажмите выпадающий список Notification Policy и выберите одну или несколько политик уведомлений, созданных на платформе.
-
Выберите Alert Notification Interval, настройте интервал отправки сообщений об оповещениях с момента срабатывания оповещения до его возврата в нормальное состояние.
-
Global: Использовать глобальную конфигурацию по умолчанию платформы. Глобальные конфигурации поддерживают обновления.
-
Custom: После выбора Custom можно настроить интервал отправки сообщений, нажав на выпадающий список рядом с уровнем оповещения.
Примечание: При выборе No Repeat отправляется только одно сообщение при срабатывании оповещения и при его возврате в норму.
Завершение
После проверки правильности введённой информации нажмите Create для завершения операции. Вы можете управлять и просматривать текущий статус каждой политики (например, было ли сработано оповещение) в списке политик оповещений.
Создание политик оповещений с использованием шаблонов
Используйте созданные на платформе шаблоны оповещений для быстрого создания политик оповещений для указанных вычислительных компонентов.
Предварительные условия
-
Администраторы создали шаблоны оповещений для вычислительных компонентов на платформе ( Platform Management View > Operations Center > Alerts > Alert Templates).
-
Убедитесь, что в кластере, где расположены ресурсы политики оповещений, развернут компонент мониторинга, чтобы созданные на основе метрик мониторинга политики оповещений были активны.
-
Убедитесь, что в кластере, где расположены ресурсы политики оповещений, развернут компонент Elasticsearch, чтобы созданные на основе логов и результатов запросов по событиям политики оповещений были активны.
Шаги
- В левой навигационной панели нажмите Alerts > Rules.
- Нажмите на
 рядом с кнопкой Create Rule > From Template.
рядом с кнопкой Create Rule > From Template. - Настройте основную информацию политики оповещений и выберите Resource Object и Belonging Cluster.
- Нажмите Create.
Последующие операции
Просмотр оповещений в реальном времени
Вы можете просматривать текущий статус оповещений созданных вами политик в списке политик оповещений.
Кроме того, для более наглядного отображения текущей ситуации с оповещениями платформа предоставляет панель Real-time Alerts, которая централизованно отображает ресурсы, на которых в данный момент срабатывают оповещения, уровень влияния оповещений и подробную информацию об оповещениях в кластерах текущей сервисной сетки, к которым у вас есть права доступа. Это облегчает операционному персоналу и разработчикам получение оперативного обзора общей ситуации с бизнес-оповещениями на платформе, своевременное устранение причин сбоев и обеспечение нормальной работы платформы.
Отключение/включение правил оповещений
Для удобного гибкого управления правилами в рамках политики поддерживается возможность отключения/включения правил в созданных политиках оповещений. При отключении статус правила становится -, и правило не учитывается в общем количестве правил политики оповещений; при повторном включении условия срабатывания оповещения, содержащиеся в правиле, снова становятся активными.
Шаги
-
В левой навигационной панели нажмите Alerts > Rules.
-
Нажмите на Name правила, которым хотите управлять.
-
В области Alert Conditions переключите тумблер Disable/Enable рядом с правилом для его отключения или включения.