Восстановление после сбоев
Функция восстановления после сбоев в настоящее время находится в состоянии alpha. Если вы планируете использовать это решение в производственной среде, пожалуйста, используйте его совместно с такими функциями, как оповещения и регулярное резервное копирование. При этом переключение в режиме восстановления после сбоев требует ручного вмешательства, чтобы предотвратить потерю данных из-за неизвестных проблем.
Содержание
ОбзорОсновные преимуществаОписание архитектурыИдентификатор экземпляра: Service IDАрхитектура развертыванияАрхитектура развертывания в режиме Redis SentinelАрхитектура развертывания в режиме Redis ClusterОграничения и рискиОбзор
Основные функции системы охватывают всю цепочку восстановления после сбоев, включая перехват данных, разбор команд, сохранение журнала операций (Oplog), полную и инкрементальную синхронизацию данных и разбиение журнала. Рабочий процесс начинается с перехвата всех операций записи на точке входа выполнения команд. Далее система глубоко анализирует команды и преобразует их в идемпотентный, структурированный формат Oplog. Эти логи эффективно сохраняются на локальном диске, формируя полный и надежный исторический след изменений данных, что обеспечивает прочную основу для последующего восстановления данных и переключения.
В части синхронизации данных система разработала механизм, который одновременно эффективен и гибок. Он поддерживает полную синхронизацию, которая быстро строит полную копию данных на целевой стороне, генерируя RDB-снимок и комбинируя его с начальной позицией Oplog. Более того, мы инновационно внедрили механизм Offset, тесно интегрированный с Oplog, создавая возможность инкрементальной синхронизации с ультра-большим окном. В отличие от нативной репликации Redis, которая опирается на ограниченный по памяти бэклог, наш Oplog сохраняется на диске, что означает, что диапазон догоняющей инкрементальной синхронизации ограничен только дисковым пространством. Следовательно, даже если между исходным и целевым экземплярами происходит сетевой разрыв на несколько часов или даже дней, после восстановления соединения целевая сторона может запросить инкрементальные данные с последней зафиксированной точки Offset, обеспечивая эффективное догоняющее обновление данных и восстановление согласованности, что значительно повышает надежность и устойчивость архитектуры восстановления после сбоев.
Кроме того, для обеспечения долгосрочной стабильной работы системы и контролируемого использования ресурсов мы разработали функцию тонкого разбиения журнала. Эта функция автоматически прокручивает и сегментирует локальный файл Oplog в соответствии с предустановленной политикой размера. Этот механизм не только эффективно предотвращает бесконечный рост одного файла журнала и исчерпание ресурсов хранения, но и значительно облегчает архивирование, очистку и управление журналами, что является ключевой частью обеспечения непрерывной и стабильной работы службы восстановления после сбоев в производственной среде.
Наконец, система предоставляет всестороннюю и мощную наблюдаемость. Сравнивая в реальном времени последнюю позицию записи основного Oplog с синхронизированным Offset целевой стороны, система может с крайне низкими накладными расходами точно вычислять задержку синхронизации данных между исходным и целевым экземплярами. Эти ключевые показатели эффективности (KPI) могут быть бесшовно интегрированы с основными панелями мониторинга (такими как Prometheus/Grafana) и системами оповещений. Это позволяет команде эксплуатации и сопровождения в реальном времени и наглядно отслеживать состояние системы, статус синхронизации и различия в данных, чтобы своевременно вмешиваться до того, как потенциальные риски перерастут в реальные сбои, что эффективно гарантирует непрерывность бизнеса и безопасность данных.
Основные преимущества
- Высокая надежность: На основе постоянного Oplog и механизма инкрементальной синхронизации с большим окном система уверенно справляется с длительными сетевыми разрывами и задержками, обеспечивая точную фиксацию и надежное восстановление изменений данных.
- Высокая производительность: Как легковесный Redis Module, основная логика высоко оптимизирована и выполняется непосредственно в I/O потоке Redis, минимизируя влияние на основную производительность Redis.
- Высокая стабильность: Интеллектуальный механизм разбиения журнала автоматически управляет ресурсами хранения, эффективно предотвращая исчерпание дискового пространства из-за накопления журналов и обеспечивая непрерывную и стабильную работу службы восстановления после сбоев.
- Сильная наблюдаемость: Предоставляет вычисление задержки с точностью до уровня операций и богатые показатели мониторинга, делая состояние системы полностью прозрачным, что удобно для интеграции и автоматизированного сопровождения, а также реализует активное предотвращение и контроль рисков.
Описание архитектуры
Для упрощения доступа к системе восстановления после сбоев для различных архитектур Redis мы разработали специализированный прокси-слой. В качестве ключевого компонента системы восстановления после сбоев прокси-слой предоставляет единый вход для проверки состояния и синхронизации данных в режимах Sentinel и кластера. Независимо от формы развертывания бэкенд Redis, система восстановления после сбоев взаимодействует через этот унифицированный прокси-интерфейс. Прокси-слой отвечает за инкапсуляцию внутренней логики коммуникации с конкретной архитектурой (Sentinel, кластер), тем самым отделяя систему восстановления от деталей реализации бэкенд Redis, что значительно упрощает доступ и управление экземплярами восстановления после сбоев.
Идентификатор экземпляра: Service ID
Для уникальной идентификации и управления каждым экземпляром Redis в системе восстановления после сбоев мы ввели концепцию service_id. Этот идентификатор является основным удостоверением для маршрутизации и синхронизации данных во всей системе восстановления.
- Уникальный идентификатор: Каждый экземпляр Redis для восстановления после сбоев, будь то источник или цель, должен быть настроен с глобально уникальным
service_id. Система восстановления использует этот ID для установления соответствия между источником и целью. - Диапазон значений: Допустимый диапазон
service_id—[0-15]. - Ограничение топологии: Из-за диапазона ID один источник восстановления может быть связан максимум с 15 целевыми экземплярами, поддерживая топологию «один источник — несколько целей».
Архитектура развертывания
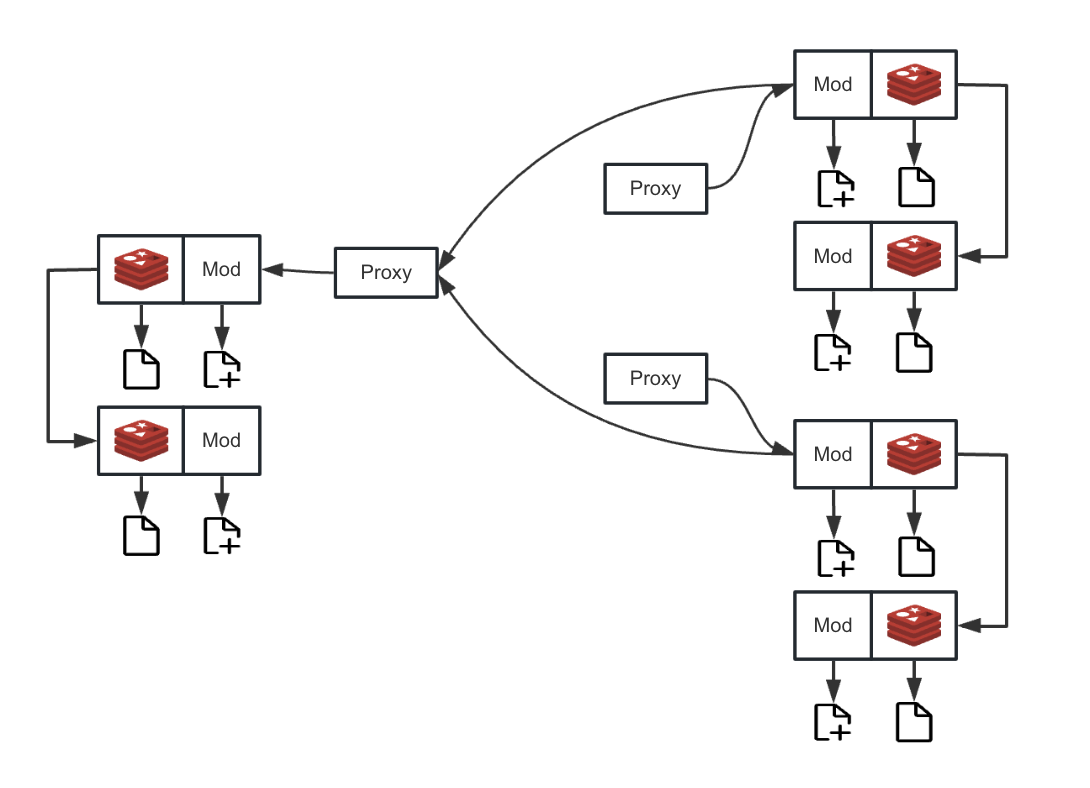
Архитектура развертывания в режиме Redis Sentinel
Когда система восстановления инициирует запрос на синхронизацию, прокси-слой запрашивает кластер Sentinel для получения информации о текущем активном мастере. После его определения прокси направляет запрос восстановления к мастеру и напрямую копирует данные между двумя сетевыми сокетами, обеспечивая производительность сетевого взаимодействия.
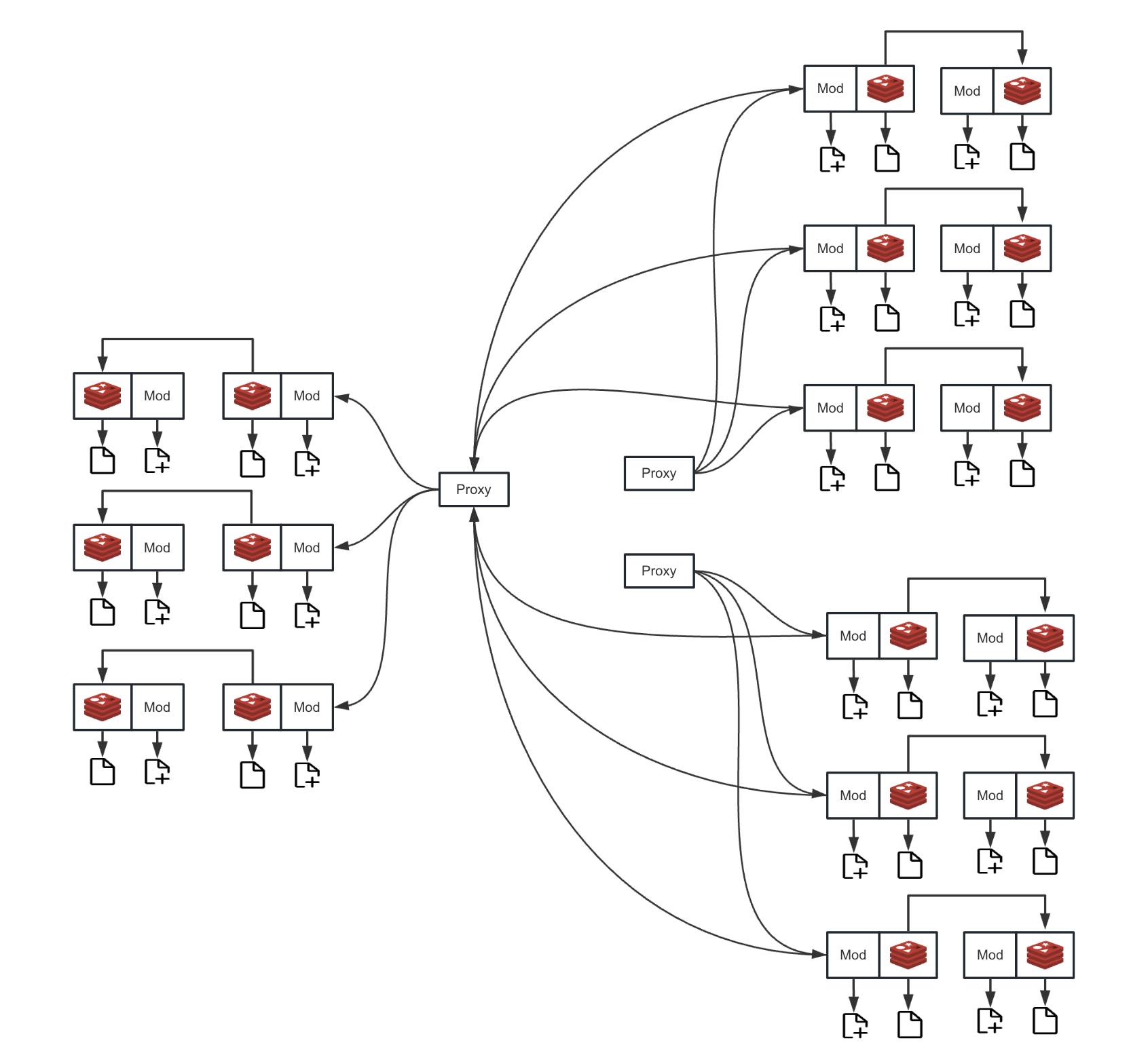
Архитектура развертывания в режиме Redis Cluster
Для кластерного режима прокси-слой отвечает за более сложный маршрутизатор шардов. Он анализирует топологию кластера и точно определяет мастер-узел, ответственный за шард, на основе информации о шарде, задействованной в запросе восстановления. Затем трафик синхронизации напрямую направляется к правильному мастеру. Этот механизм избегает затрат памяти и CPU на передачу данных в прокси-слое, обеспечивая высокопроизводительную и низколатентную синхронизацию данных в распределенной среде.
Ограничения и риски
По рискам и ограничениям восстановления после сбоев смотрите документ Disaster Recovery Limitations.